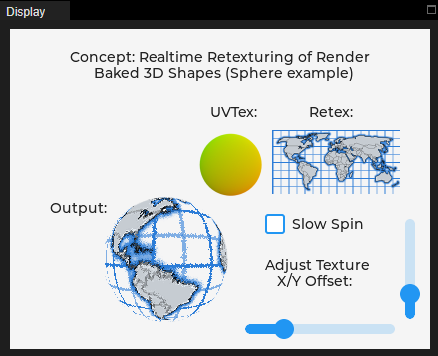
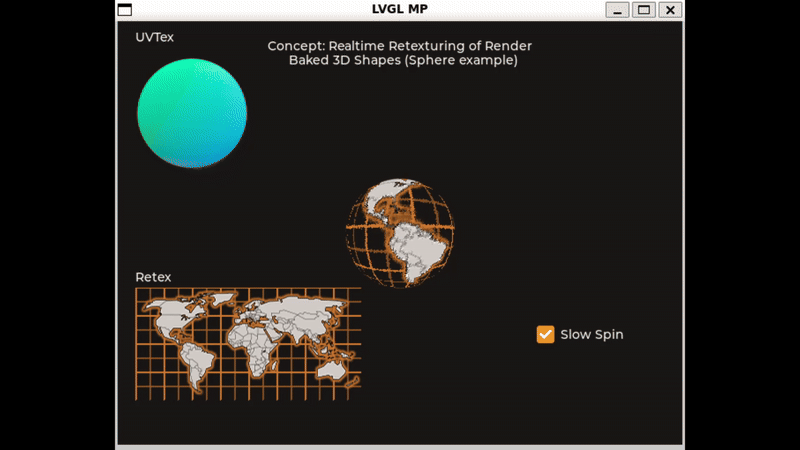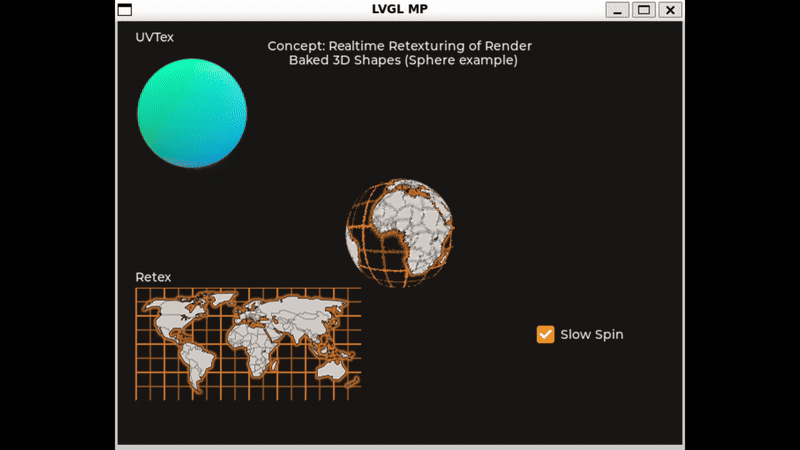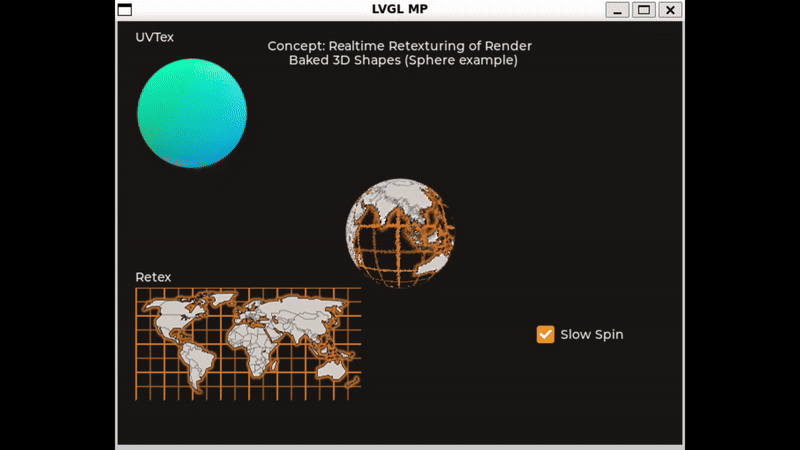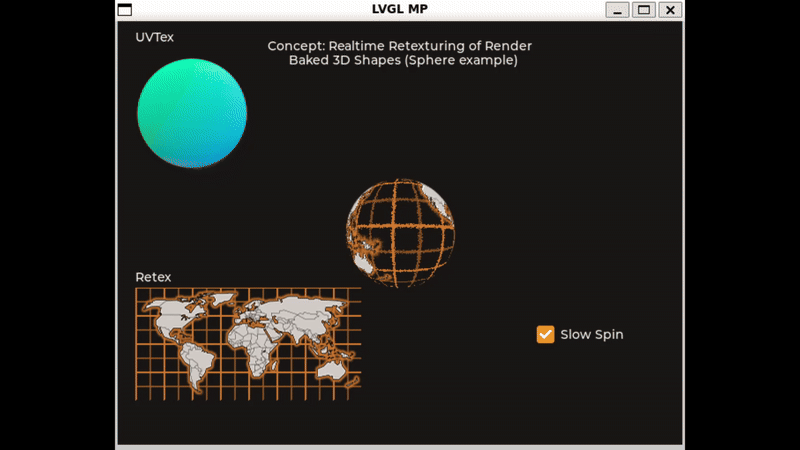
Here is a small concept sample I cooked up in the simulator. The frame rate is quite low but I think it will run better on an ESP32S3 I have here. You can try it out and use the sliders to adjust the simulated tilt. A slow timer gradually shifts the reflection around as well.
I’m programming my hardware here in C in Arduino IDE with LVGL 8.3.10 - If anyone would care to demonstrate a more performant way to accomplish this sample, I would very much appreciate it.
This same idea could also do something like “Mode 7” graphics on the SNES.
If there is a better way for me to share / update simulator scripts, please let me know.
Because the binary data used for the image sources is so large, I’ve pruned them out of this code snippet, or it exceeds the max post length. I’ll post those images as PNG files in the next reply, and you can convert them to binary yourself and paste them in to the marked areas, or maybe I can find a way to post the script without any changes in a compressed file as an attachment.
# Initialize
import display_driver
import lvgl as lv
from lv_utils import event_loop
import utime
def make_refmap():
mc20_tiny_data = bytearray(b'\x1b\x2e\x4e ... etc big binary blob here... \x4e\xff')
return lv.img_dsc_t({
'header': {'always_zero': 0, 'w': 64, 'h': 64, 'cf': lv.img.CF.TRUE_COLOR_ALPHA},
'data_size': len(mc20_tiny_data),
'data': mc20_tiny_data})
def make_sample_img():
sample_img_data = bytearray(b'\x00\x00\x00\x00 ...another large blob of binary... \x00\x00\x00\x00')
return lv.img_dsc_t({
'header': {'always_zero': 0, 'w': 128, 'h': 128, 'cf': lv.img.CF.TRUE_COLOR_ALPHA},
'data_size': len(sample_img_data),
'data': sample_img_data})
def make_output_buf():
olen = 128*128*4
return lv.img_dsc_t({
'header': {'always_zero': 0, 'w': 128, 'h': 128, 'cf': lv.img.CF.TRUE_COLOR_ALPHA},
'data_size': olen,
'data': bytearray(olen)})
def update_debug(sX, sY):
rCol = my_img_dsc.buf_get_px_color(sX, sY, lv.color_t())
rAlpha = my_img_dsc.buf_get_px_alpha(sX, sY)
outimage_dsc.buf_set_px_color(sX, sY, rCol)
outimage_dsc.buf_set_px_alpha(sX, sY, rAlpha)
debuglabel.set_text('sX:'+str(sX)+' sY:'+str(sY)+' -> [R:'+str(rCol.ch.red)+' G:'+str(rCol.ch.green)+' B:'+str(rCol.ch.blue)+' A:'+str(rAlpha)+']')
def update_output():
global last_update_line
global last_offX, offX, offX_dirty
global last_offY, offY, offY_dirty
if (offX_dirty or offY_dirty):
last_offX = offX
last_offY = offY
debuglabel.set_text('offX:'+str(offX)+' offY:'+str(offY)+'\n timerX:' +str(timerX))
else:
return
oX = last_offX + timerX
oY = last_offY + timerX
for isY in range(0,32):
sY = (last_update_line + isY) % 128
for sX in range(0,128):
rCol = my_img_dsc.buf_get_px_color(sX, sY, lv.color_t())
if (rAlpha > 0):
rAlpha = my_img_dsc.buf_get_px_alpha(sX, sY)
# rX = (int((rCol.ch.red * 64) / 255) + oX) % 64
# rY = (int((rCol.ch.green * 64) / 255) + oY) % 64
rX = ( (rCol.ch.red >> 2) + oX ) % 64
rY = ( (rCol.ch.green >> 2) + oY ) % 64
rmCol = mc20_tiny_dsc.buf_get_px_color(rX, rY, lv.color_t())
outimage_dsc.buf_set_px_color(sX, sY, rmCol)
outimage_dsc.buf_set_px_alpha(sX, sY, rAlpha)
last_update_line += 32
if (last_update_line >= 128):
last_update_line = 0
if (last_offX != offX):
offX_dirty = True
else:
offX_dirty = False
if (last_offY != offY):
offY_dirty = True
else:
offY_dirty = False
def timer_small_tick():
update_output()
outimage.invalidate()
def timer_big_tick():
global timerX, offX_dirty
timerX = (timerX + 1) % 128
offX_dirty = True
def hslider_event_cb():
global offX, last_offX, offX_dirty
offX = 64 - hslider.get_value()
if (last_offX != offX):
offX_dirty = True
def vslider_event_cb():
global offY, last_offY, offY_dirty
offY = 64 - vslider.get_value()
if (last_offY != offY):
offY_dirty = True
offX_dirty = True
offY_dirty = True
last_offX = -1
last_offY = -1
offX = 64
offY = 64
timerX = 0
last_update_line = 0
scr = lv.obj()
debuglabel = lv.label(scr)
infolabel1 = lv.label(scr)
infolabel2 = lv.label(scr)
infolabel3 = lv.label(scr)
my_img_dsc = make_sample_img()
img1 = lv.img(scr)
img1.align(lv.ALIGN.CENTER, 0, 0)
img1.set_src(my_img_dsc)
img1.set_pos(-120, -45)
mc20_tiny_dsc = make_refmap()
refmap = lv.img(scr)
refmap.align(lv.ALIGN.CENTER, 0, 0)
refmap.set_src(mc20_tiny_dsc)
refmap.set_pos(10, -50)
outimage_dsc = make_output_buf()
outimage = lv.img(scr)
outimage.align(lv.ALIGN.CENTER, 0, 0)
outimage.set_src(outimage_dsc)
outimage.set_pos(-55, 70)
debuglabel.align(lv.ALIGN.BOTTOM_RIGHT, -65, -65)
infolabel1.align(lv.ALIGN.TOP_MID, 0, 5)
infolabel2.align(lv.ALIGN.TOP_LEFT, 30, 45)
infolabel3.align(lv.ALIGN.BOTTOM_RIGHT, -70, -115)
infolabel1.set_text("Concept: Realtime Application of Tilt Shifted\n"
"Reflection Map onto Screen Space Normals")
infolabel2.set_text("Baked Normals: \n"
" Refmap:\n\n\n\n\n\n\n\n"
"Output:")
infolabel3.set_text("Simulate Tilt\nAdjustment:")
hslider = lv.slider(scr)
hslider.set_width(150)
hslider.set_height(20)
hslider.set_range(-64,64)
hslider.align(lv.ALIGN.BOTTOM_RIGHT, -35, -15)
hslider.add_event_cb(lambda e: hslider_event_cb(), lv.EVENT.VALUE_CHANGED, None)
vslider = lv.slider(scr)
vslider.set_height(150)
vslider.set_width(20)
vslider.set_range(-64,64)
vslider.align(lv.ALIGN.BOTTOM_RIGHT, -15, -35)
vslider.add_event_cb(lambda e: vslider_event_cb(), lv.EVENT.VALUE_CHANGED, None)
update_debug(42,24)
update_output()
timer1 = lv.timer_create(lambda e: timer_small_tick(), 25, None)
timer2 = lv.timer_create(lambda e: timer_big_tick(), 200, None)
lv.scr_load(scr)