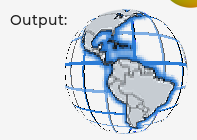
Hi just wanted to update on something I’m working on here. As kdschlosser mentioned, resources on MC’s are very sparse so the less RAM we can use with this the better. To that end, I’m working on a way to store the UVTex (or NormalTex) images at extremely low resolution, and then interpolate the sparse data up to the required resolution at runtime (without baking that scaled image into a new larger image which would itself use up the RAM we’re trying to save).
Results are very promising so far. I have made a version of the UVTex above that’s normally at 128x128x4, and instead it’s at 32x32x4 and will soon be 32x32x2. It seems that interpolating the ‘in-between’ pixels produces results that are accurate enough to be acceptable, with some dodgey bits around the edges I’m still working on. So the image quality is good enough, unfortunately the runtime speed took an absolute nose-dive trying it this way, and I’m still struggling with more ways to optimize it back into the acceptable range. The main problem is that to do this interpolation, I have to sample 4 source pixels per output pixel, and that gets expensive.
One strategy I’m trying now is recycling 2 of those lookups per cycle, so the new Upper-Left and Lower-Left pixels are just the last cycles Upper-Right and Lower-Right pixels. Maybe I can have that ready to demo soon and hopefully that will help shave some clock cycles off the process
If anyone has any suggestions for the most performant way to sample, for example, a 32x32 bitmap at 128x128 resolution without using 128x128x4 ram to store a buffered copy of the rescaled tiny version, let’s hear it I’m all ears.
If this approach can be made fast enough, we could concievably store these lookup textures at rediculously low resolution, and then mask them out with much more compact 1/2/4 bit alpha images so for example the edges of the circle can be nice and sharp.
Gotta work tho so I’ll be out a while, will update tomorrow sometime with screenshots and samples.
EDIT: I see the forum software is advising people not to reply further because this problem has been solved. I think in this case, this problem could never be solved enough, so if anyone has further thoughts please feel free to provide them, even if it’s years later.