Did you use 2 screen sized buffers for LVGL in v7? If so it really can be slower in v8 because in v7 the 2 buffer were synchronized internally and only the changed areas where redrawn. In v8 this feature doesn’t exist.
You can also try the latest master branch of LVGL, where the display needs to be created a little bit differently but the v7 like buffering is added again if you use DIRECT_MODE with 2 screen sized buffers. Please check out this post for more details about the news in master
Hi,@ kisvegabor,
Many thanks!
Yes, both V7 and V8 are full screen size buffer and the V8 is in direct mode as below and manually copy the invalid area to another buffer for sync in the disp_flush() .
You means V8 will redrawn all widget each cycle even in the direct mode?
I have tried V9, result neally the same FPS with the V8. I have set the display in direct mode there and
copy the invalid area manually as in V8. You means no need to copy the invalid area in V9? I will try.
I also doubt maybe the huge amount event interfere the drawn, when I press the touch pad to scroll the marker on the chart , as the fact the V8 have much FPS dropped than the V7 in the same case.
Hi,@ kisvegabor,
Many thanks!
If the direct mode of V8 equal to the V7, why the refresh rate differ so much? But per the bench mark test, the V8 win the V7. It is really confusing.
I will test the V9 in detail.
Do you have some sample code for the lv_port_disply for TWO screen-sized buffer in V9? My porting won’t work without the manually invalid area copying.
In the disp_flush(), trigered an ISR and switch the frame buffer address in the ISR.
I have found that the display will not proper sync. even without the DMA2D functions, if not doing the manual copy. If I do as V8 , it display normally.
It can’t work and if bypass the code for copying the invalid area in the _lv_disp_refr_timer(), instead by the manual copying as V8, it works.
The FPS of the live waveform chart is similar to the V8 , around 8, vs 11 in V7 ,and also drop to 6 when keeping scrolling the marker, same with V8 and slower than the 10 in V7.
Where might be the bottleneck of the scrolling speed comparing to the V7?
I had enabled the DMA2D in both case.
The bench mark example can’t running and I am trying fixing. The wigget and music example work well. The speed when scrolling the tabview page in the widget example is similar to my waveform chart
Hi,@ kisvegabor,
Many Thanks!
The fix worked! I made a mistake yesterday
But the bench mark example still can’t running. It is running to a hardfault. Does it work in your side?
Hi,@ kisvegabor,
Many Thanks!
When just running the bench mark example , it works but look abnormal, please refer to the photo. Something is wrong under the LV_DEMO_BENCHMARK_MODE_RENDER_ONLY mode.
Hi,@kisvegabor,
When define the #define LV_USE_GPU_STM32_DMA2D 0 , the bench mark result is the same with when it is on.
But the lv_draw_stm32_dma2d_blend_map() is really executed when using the DMA2D.
Hi,@kisvegabor,
Many thanks!
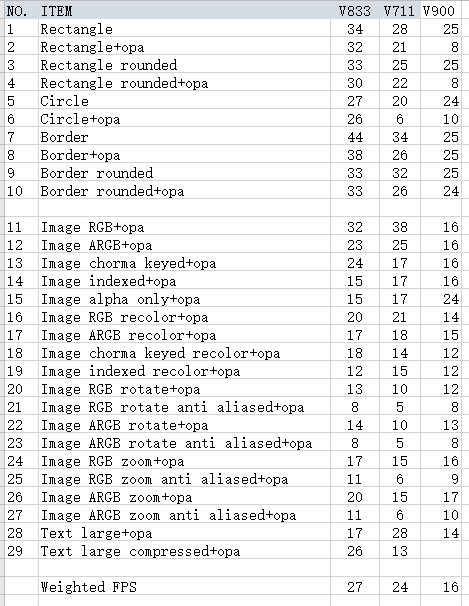
Per my benchmark test , the V8 is the fastest , but in my project the V7 is the winner and nearlly 20% faster than the V8. What might be the reason and any possible optimization?
I hope the V9 catching up soon.