I have gotten LVGL working quite well, with multiple ways of drawing to the LCD display on my device.
At the moment I store the framebuffers in 32MB SDRAM. The drawing itself is naturally (much) slower than when using SRAM.
However, considering I have a huge amount of memory available now, would it make sense to use more than 2 framebuffers? Would this speed up drawing at all?
Right now I use two framebuffers, and switch between these when the LVGL flush callback is called. Instead of toggling two framebuffers I could go through a list of more than 2. It seems LVGL is mostly built for two framebuffers at the moment, as you can only pass 2 framebuffers to the lv_disp_draw_buf_init() function.
the use of 2 frame buffers is if you are using DMA memory. Chances are that you are not because of the type of memory you are using. If it is octal SPI memory then you may have a change that it is about to be used as DMA memory. DMA memory doesn’t require the processor in order to move data to and from the memory. So while you are sending one frame buffer then LVGL is able to be off filling the other one.
That is pretty much the use case for 2 frame buffers.
Thanks, KD
I actually am using DMA to transfer the data. My specific MCU has a DMA controller on it which allows me to still transfer to frame buffers without hogging the CPU. Even from internal RAM to external memory.
After thinking about it some more it seems useless to use more than 2 framebuffers. Seeing as displaying the image takes less time than drawing it (at least in my case), there’s no reason to have some sort of “buffer” of multiple framebuffers.
make the buffer smaller so the time it takes to transfer the buffer data to the display is less.
What you have to remember is this. if it takes 20 milliseconds to write the buffer to the display and it takes 10 milliseconds for LVGL to fill the buffer then you would have a savings of 10 milliseconds each time around. if it takes only 10 milliseconds to empty the buffer and it takes 20 milliseconds for LVGL to fill the buffer there is a 10 millisecond savings each time around.
The trick is you have to register a callback with the MCU for when the buffer gets emptied and in that callback you call flush_ready. if you are calling flush_ready in the flush function or you are using only a single buffer you are not getting any of the performance gains that using DMA is going to give. This is because the program stalls until that buffer gets emptied. You don’t want to write to a buffer that is being red from at the same time, you will end up with corruption of the data which is why the stall occurs.
by using DMA the processor isn’t getting tied up with dealing with memory reads so the program is allowed to continue to run while this is taking place. Hence the need for 2 buffers. so while the first is being written to the display the program continues along its way and it will fill the second buffer. If the second buffer is ready to be written but the first has not finished being written to the display then the program will stall until that first one is finished so it can be used by LVGL until the second one if done being written to the display.
What tells LVGL that a buffer has finished being written to a display is the call to flush_ready.
There is always a speed increase from using DMA and 2 buffers. what will make a large impact in performance when using DMA with the 2 buffers is the size of the buffer. To big a buffer and performance will decrease to small a buffer and performance will decrease. so if you have the buffer sizes set to be too large it could cause a performance drop that would make it run slower than if using a single buffer if the single buffer is a smaller size.
there is no “magic” number here on what to set the buffer size(s) to. You are going to have to play around with it until you find the “sweet spot” where you get the best performance from it. Too many variables come into play and it has to be done for each application.
I believe the general rule of thumb is anywhere between 1/8 and 1/4 of the total area of the display times the color depth. I could be wrong on that and maybe someone will want to chime in if they have information.
You are correct, we have just switched to using a large 800x480 display and the performance is nothing at all like the 480x272 display we were using previously.
Methods that made the system run extremely smooth before now seem to be slower and one of the slower methods is now one of the fastest. Quite interesting.
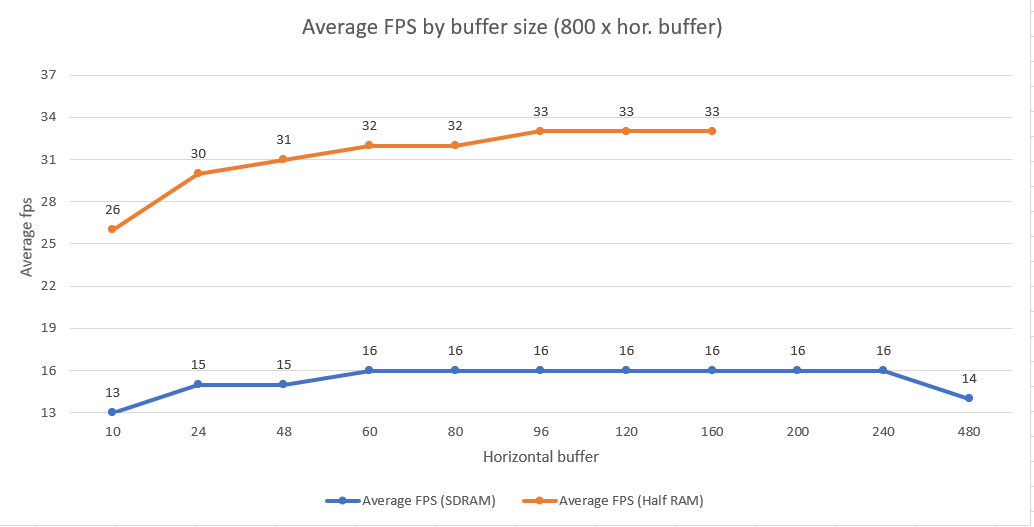
Because of the large size of the display I really cannot excuse placing the (partial) display buffers in RAM anymore, hence I have to use SDRAM: I think this is now the limiting factor, see the graph below based on lv_benchmark results. This is with 2 display buffers and DMA. Of course it is still possible to place the partial display buffers in RAM, but this is quite a waste of precious memory: for instance the option with 10 horizontal pixels already takes up 32KB. (The orange line is with display buffers in RAM!)
In fact, at this point drawing directly to the frame buffers (stored in SDRAM) used for my screen with direct_mode and full_refresh on is actually not too bad performance-wise with an average FPS of 22.
This seems to be a case of diminishing returns. The (SD)RAM usage expands while the actual performance is bottlenecked by the use of SDRAM for storing frame buffers.
if using the SPIRAM for non “mission critical” portions of your code where speed is not the highest priority then I would suggest doing that. You should be able to set into partial mode and create 2 smaller frame buffers that will fit into the fast memory and use the SPIRAM for the rest of the code. Performance wise writing and reading small things from the SPIRAM isn’t that bad. you really notice it when you are dealing with large amounts of data that get moved at once. The other thing is that a lot of times the SPIRAM is on a shared bus with the flash so if you have anything that uses the flash like reading of PNG data this can slow down transfers to and from the SPIRAM as well.
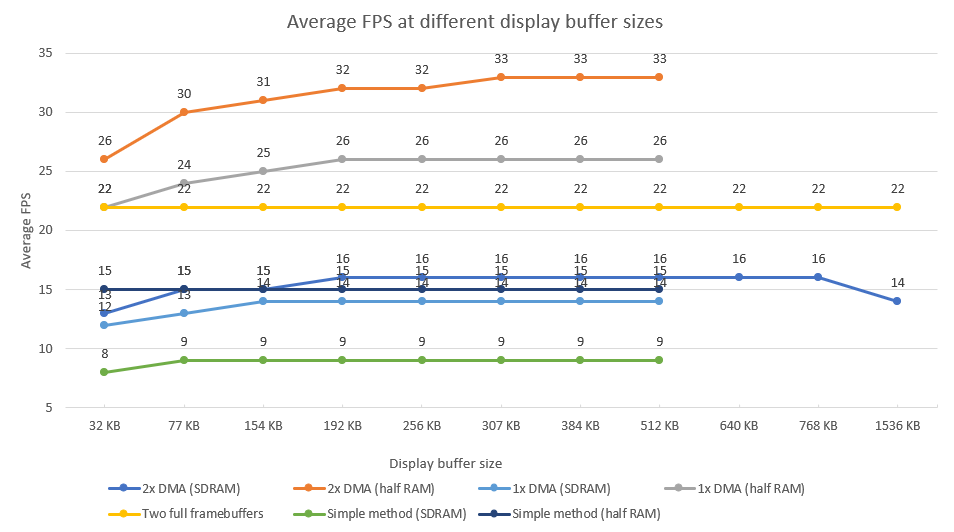
Have you graphed what the speed is with a single frame buffer? It would be interesting to see what the speed difference would be there.
It is obvious from these results that placing the display buffers in SDRAM is not really a viable option. The “half RAM” option is always faster, but again this comes at a cost of precious memory.
I thought it was quite interesting to see that a single DMA buffer is still quicker than my “simple method” which works in the exact same way but no DMA.
EDIT: changing the optimization to -O3 instead of -O2 nets a small performance increase. The 2x DMA (half RAM) solution now reaches 30fps with a total display buffers size of 32KB. Which is the refresh rate of the screen anyway.