I wanted to share my experience here as well.
Warning: wall of text ahead, but I hope people may find this useful.
I am using a custom board with STM32H723 @ 550 MHz, with 16 MiB SDRAM at 130 MHz
Display: 800x480 24-bit parallel via LTDC
LVGL release 8.3.11
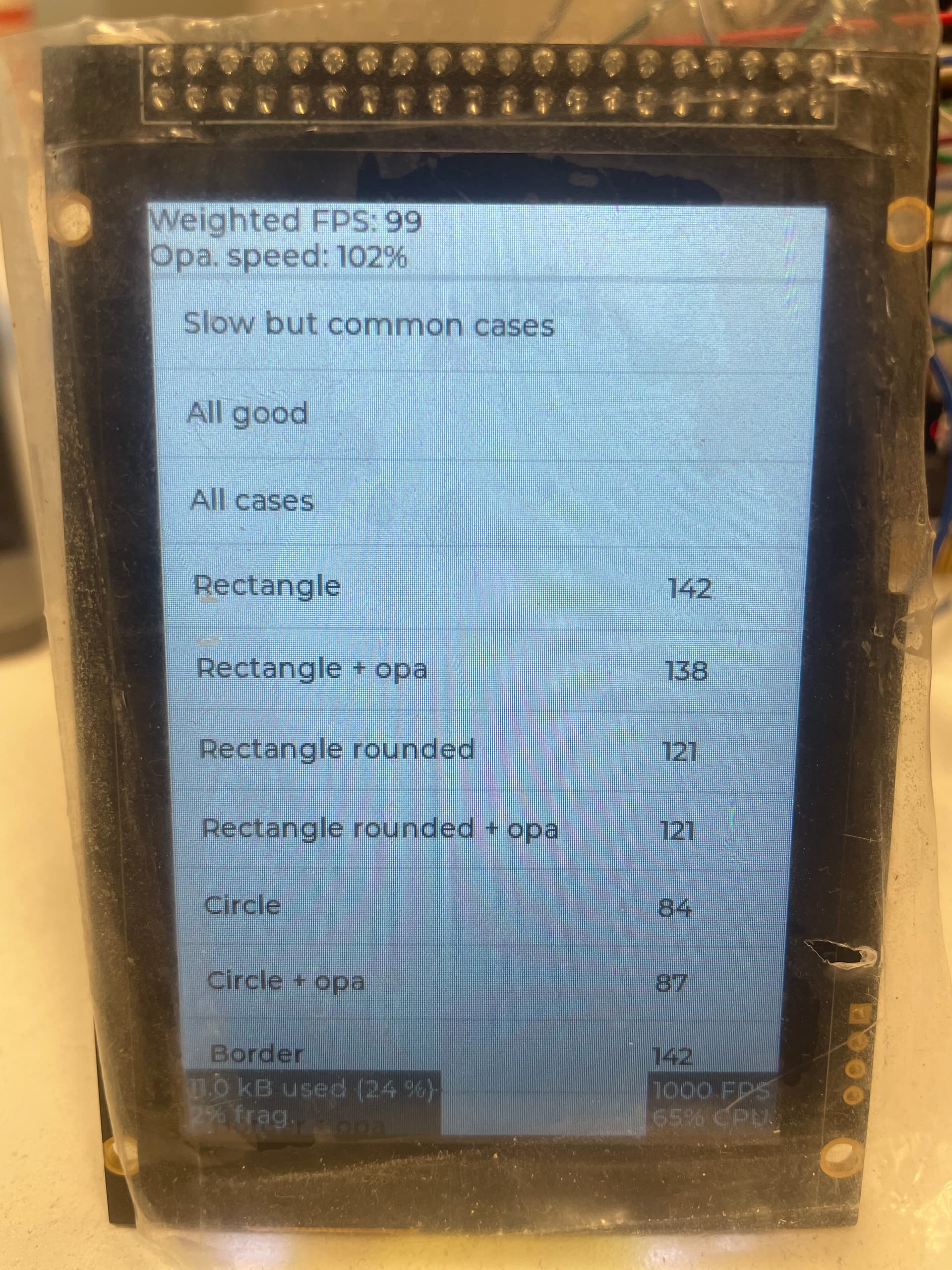
lv_demo_benchmark FPS: 82
Bonus feature: Adaptive refresh rate (!!)
The main bottleneck is SDRAM bandwidth
Currently using ARGB8888 everywhere, because the LVGL DMA2D implementation does not support RGB888. Since we are bandwidth limited, RGB888 support would most likely improve performance by another 25%. We could disable DMA2D, but we want to be able to give CPU time to other RTOS tasks while rendering (semaphore in wait_cb).
Buffers
Dual SRAM buffers for LVGL+DMA2D rendering (800*40 pixels).
AND
Dual framebuffers in external SDRAM (offset by 4 MiB, so they are placed in different internal banks). Not only does this result in tear-free rendering but actually improves worst-case performance (full-screen updates) when compared to a single framebuffer (see: AN4861 4.5.3). There is a catch though, see below.
Flush with MDMA
DMA2D is already in use for rendering, but we still want to copy in parallel. So we use MDMA.
The MDMA “repeated block transfer” is perfectly suited to do a 2D copy, started in the flush_cb.
The burst size should be set to some higher value, e.g. MDMA_DEST_BURST_16BEATS, but be careful not to starve LTDC.
Catch
This setup does not seem to be directly supported by LVGL (2x internal buffer + 2x framebuffer).
The main problem seems to be, that after a buffer swap, some pixels will need to be copied between the two framebuffers in the external SDRAM to keep them in sync before rendering the next change. Since we are bandwidth limited, re-drawing the entire screen can actually give better performance than trying to re-use those pixels.
For this, we use:
lv_obj_invalidate(lv_scr_act()); → _lv_disp_refr_timer(NULL); and friends.
In a way, this is optimized for full screen redrawing (full-screen menu scrolling, etc.). But the disadvantage is less efficiency for small updates, and slowdown when there is a lot of overdraw. e.g. birthday date picker in widgets demo.
However, we can add an optimization where smaller updates still go directly to the front buffer without a full redraw.
Adaptive refresh rate
This lets everything stay smooth even if you dip below the refresh rate of the screen.
It is actually quite simple to implement:
We have setup the line event interrupt in LTDC to trigger just before the scanout of the new frame begins.
Depending on your display timings, this could be e.g. line 510 (blanking must be accounted for).
In the interrupt, we check if LVGL has finished rendering. lv_disp_flush_is_last() is helpful here.
If it has, just swap the buffers as normal
If it has not finished rendering we temporarily stop the clock to the display:
__HAL_RCC_LTDC_CLK_DISABLE();
Careful: LTDC registers can no longer be accessed after this.
Then after rendering is done re-enable the clock again:
__HAL_RCC_LTDC_CLK_ENABLE();
and then swap the buffers.