I am trying to use DMA (Direct Memory Access) so I can transfer data between a framebuffer filled by LVGL and the framebuffer my LCD screen interface uses.
The problem is as follows:
my LCD screen interface uses an array with the size of my screen
At the moment I fill this array using the flush callback:
However, I want to use DMA to transfer the data from the area and p_color parameters of the flush_callback to this fb_background[0] array used by the LCD. The problem is that the area parameter does not translate nicely to a pointer inside that array that can just be incremented.
I cannot simply transfer x amount of pixels because the fb_background[0] address needs to be incremented by the screen width for every y pixels in the area parameter.
What MCU/Processor/Board and compiler are you using?
I am using a Renesas RA6M3G Evaluation Kit
What LVGL version are you using?
LVGL Version 8.3
What do you want to achieve?
I want to transfer data using DMA (Direct memory acces). From the buffer filled by LVGL functions, to the framebuffer used by the LCD interface.
What have you tried so far?
I have looked at the Renesas documentation for both of its data transfer options (r_dtc and r_dmac). However, I really do not understand how to implement this with LVGLs flush function.
I got as far as drawing a single line (consisting of the horizontal resolution x horizontal lines in a framebuffer) of a still image.
I could increment the pointer of my screen’s framebuffer by the horizontal lines of the LVLGL framebuffer to fill the whole screen.
However this will quickly become an issue when the area passed to the flush callback is not of the same dimensions as my smaller LVGL framebuffer. The point is that an area does not translate well to the framebuffer that the screen expects.
To use DMA I need to be able to transfer one continuous “block” of data from the smaller LVGL framebuffer directly to the correct location in my screens framebuffer. Is this possible without just using an LVGL framebuffer that takes up the size of the whole screen and combining that with direct_mode? (this defeats the entire purpose of DMA in this case).
I was going to check the daatasheet on that MCU but I would have to create an account in order to download anything. I need to see the data sheet on how the display portion of it works.
Maybe somethink missunderstand. Most LCD drivers work with two transaction mode. First set window and second send data. For example ESP have transaction queue support, then you can send more transactions before wait to complete is required. This enlarge ofcourse ram usage for store transaction data.
Normal for example SPI in flush callback check and wait to previous complete… set window … start DMA data. If your config is ok then area equal to window and color array is perfectly aranged for DMA.
as far as I am aware, that is not how it works in this case.
I make use of a graphics interface to send signals to the LCD. This makes use of at least one configured framebuffer where the entire screen is placed in an array of “pixels” (RGB565 means every pixel is made up of two bytes).
So in practice there is an array like this: uint8_t frameBuffer[VER_SIZE * HOR_SIZE *2]
So to write pixels to this array (and by extension the screen) I have to calculate the position inside this framebuffer based on the area. This means that I cannot send the entire area as one continuous “block” of data using DMA; I would have to make it continuous first which defeats the purpose of using DMA here.
edit: it turns out the position of the frame can be changed, but this is only part of the solution… the width and height needs to correspond to the area too…
You speak about RGB displays (without internal framebuffer), then i mean your idea is waste power.
For hw accelerated you need optimized libraries as TouchGFX or other, that uses LTDC + D2DMA
In lvgl i see only direct mode + maybe gpu callbacks.
Direct mode can use in double buffering sync over some DMA … if you update full width then one block DMA can be used for y1 - y2 area. Read direct mode docu.
Better question is if one buffer used howto sync direct rendering to screen blanking …
I have already succesfully used two full sized framebuffers and direct_mode with LVGL. Just toggling in between these buffers while LVGL filled them, works well but it takes up a lot of memory.
Updating the full width with DMA works well too.
But once, for instance, a button is pressed, it will mess up the rendering completely because it tries to draw at another location on the screen entirely.
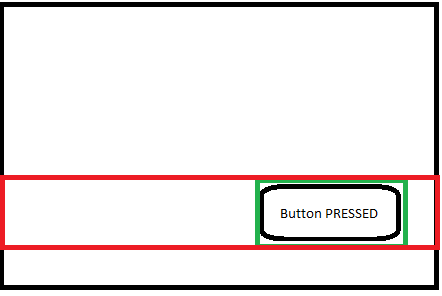
Sorry to bother you, @kisvegabor, but is there anything built into LVGL to re-render the entire width of a screen with the height of the changed object? I hope this image clarifies it a bit:
So instead of the area being the green box, it would be really useful in this case if the area was the red box.
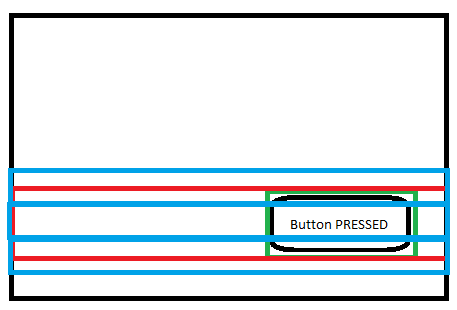
Or perhaps re-render it in parts based on a partial framebuffers size. The blue lines in the image below represent partial framebuffers: once again using all pixels inside the boxes; even those that have not changed.
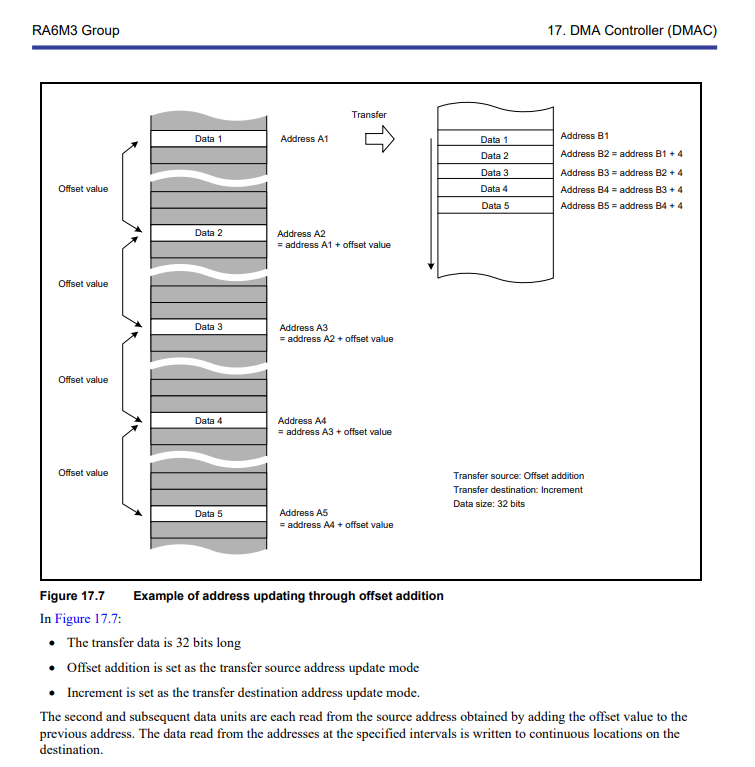
I had a quick view at the RA6M3 user’s manual:
There are more complex DMA modes. Maybe you take a look at section 17.3.2 and 17.3.3.
It might be not easy to understand, but for me it seems to be that you can transfer the ‘green’ source area to the destination area with DMA.
I finally got it working! The solution above that I thought would work is actually a bit over the top for this use case.
I will not bore you will the details: basically all I had to do was:
Set both source and destination to increment by one “data unit” (2 bytes) per transfer.
Set the source for DMA transfer to the color_p pointer in the flush callback.
Set the destination pointer to the appriopate pointer in my screens framebuffer array.
Set a “transfer size” at the width of one line (area.x2 - area.x1)
Set a “number of blocks” (number of repeats) at the height of the area (area.y2 - area.y1)
Make it so that an interrupt is triggered for each line on the display when finished transferring.
Inside this interrupt, change the DMA’s destination adress by adding the total horizontal width.
The performance gain with DMA is quite substantial!
For instance: with one full framebuffer (272x480) transfer via DMA I get 115 avg. fps in the lv_demo_benchmark. This uses 571KB of RAM (not strange, considering I have two full-sized framebuffers!).
When using double buffering, with two full sized frame buffers but no DMA the average fps is 78, with a slightly higher RAM usage at 588KB (altough that might be up to other factors too! it’s been a while).
When using double buffering with two half sized framebuffers, with DMA the average fps is 133! and 571KB RAM used.
Both of these three solutions are of course not ideal because of the high RAM usage. But lowering the size of the framebuffers saves a lot of memory at the cost of graphical fidelity.
Thanks a lot @kdschlosser and @robekras (and everyone else) for your help. This has really doubled the application’s performance.
In case you didn’t already catch it, you have a 1-off error in your code above. Reason: area.x2 is the last column within the object, and area.y2 is the last row. So the corrected width and height would be (respectively):
(area.x2 + 1 - area.x1)
and
(area.y2 + 1 - area.y1)
I hope that helps. (I’m working on a DMA solution now, so this jumped out at me.)