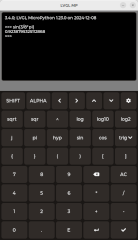
With your specific use case it is going to be better if you roll your own keyboard plugin.
One of the things that I have learned with using LVGL is to use the lv.obj as a container. What you do is you create a style that sets all colors to black, all of the opacity to 0. set the pads, margins, border widths, shadow settings, outline widths all to 0.
here is an example of what I am talking about…
import lvgl as lv
CALC_BUTTON_PRESSED = lv.event_register_id()
class Button(object):
def __init__(self, parent, label, keycode):
self.parent = parent
self.keycode = keycode
self.obj = obj = lv.button(parent.obj)
self.label = lv.label(obj)
self.label.set_text(label)
obj.set_style_text_color(lv.color_hex(0x00FF00), lv.PART.MAIN)
obj.set_style_text_color(lv.color_hex(0xFF0000), lv.STATE.PRESSED)
obj.set_style_bg_color(lv.color_hex(0x000000), lv.PART.MAIN)
obj.set_style_bg_opa(255, lv.PART.MAIN)
obj.set_style_border_width(2, lv.PART.MAIN)
obj.set_style_border_color(lv.color_hex(0x00FF00), lv.PART.MAIN)
obj.set_style_border_opa(255, lv.PART.MAIN)
obj.set_style_border_opa(0, lv.STATE.PRESSED)
obj.set_style_margin_bottom(0, lv.PART.MAIN)
obj.set_style_margin_left(0, lv.PART.MAIN)
obj.set_style_margin_right(0, lv.PART.MAIN)
obj.set_style_margin_top(0, lv.PART.MAIN)
obj.set_style_outline_color(lv.color_hex(0xFF0000), lv.PART.MAIN)
obj.set_style_outline_pad(0, lv.PART.MAIN)
obj.set_style_outline_width(2, lv.PART.MAIN)
obj.set_style_outline_opa(0, lv.PART.MAIN)
obj.set_style_outline_opa(255, lv.STATE.PRESSED)
obj.set_style_pad_left(0, lv.PART.MAIN)
obj.set_style_pad_right(0, lv.PART.MAIN)
obj.set_style_pad_top(0, lv.PART.MAIN)
obj.set_style_pad_bottom(0, lv.PART.MAIN)
obj.set_style_radius(5, lv.PART.MAIN)
obj.set_style_shadow_offset_x(2, lv.PART.MAIN)
obj.set_style_shadow_offset_y(2, lv.PART.MAIN)
obj.set_style_shadow_color(lv.color_hex(0xC0C0C0), lv.PART.MAIN)
obj.set_style_shadow_opa(210, lv.PART.MAIN)
obj.set_style_shadow_opa(0, lv.STATE.PRESSED)
obj.set_style_shadow_spread(5, lv.PART.MAIN)
obj.set_style_shadow_width(3, lv.PART.MAIN)
obj.remove_flag(lv.obj.FLAG.EVENT_BUBBLE)
obj.remove_flag(lv.obj.FLAG.SCROLLABLE)
obj.add_event_cb(self.on_pressed, lv.EVENT.PRESSED, None)
def on_pressed(self, evt):
evt.stop_bubbling()
self.obj.send_event(CALC_BUTTON_PRESSED, self)
def set_pos(self, x, y):
self.obj.set_pos(x, y)
def set_size(self, width, height):
self.obj.set_size(width, height)
self.obj.layout()
self.label.center()
def get_keycode(self):
if self.keycode is None:
return self.label.get_text()
return self.keycode
class Container(object):
def __init__(self, parent):
if hasattr(parent, 'obj'):
self.parent = parent
self.obj = obj = lv.obj(parent.obj)
else:
self.parent = None
self.obj = obj = lv.obj(parent)
obj.set_style_bg_color(lv.color_hex(0x000000), lv.PART.MAIN)
obj.set_style_bg_opa(0, lv.PART.MAIN)
obj.set_style_border_opa(0, lv.PART.MAIN)
obj.set_style_border_width(0, lv.PART.MAIN)
obj.set_style_margin_bottom(0, lv.PART.MAIN)
obj.set_style_margin_left(0, lv.PART.MAIN)
obj.set_style_margin_right(0, lv.PART.MAIN)
obj.set_style_margin_top(0, lv.PART.MAIN)
obj.set_style_outline_opa(0, lv.PART.MAIN)
obj.set_style_outline_pad(0, lv.PART.MAIN)
obj.set_style_outline_width(0, lv.PART.MAIN)
obj.set_style_pad_left(0, lv.PART.MAIN)
obj.set_style_pad_right(0, lv.PART.MAIN)
obj.set_style_pad_top(0, lv.PART.MAIN)
obj.set_style_pad_bottom(0, lv.PART.MAIN)
obj.set_style_radius(0, lv.PART.MAIN)
obj.set_style_shadow_offset_x(0, lv.PART.MAIN)
obj.set_style_shadow_offset_y(0, lv.PART.MAIN)
obj.set_style_shadow_opa(0, lv.PART.MAIN)
obj.set_style_shadow_spread(0, lv.PART.MAIN)
obj.set_style_shadow_width(0, lv.PART.MAIN)
obj.remove_flag(lv.obj.FLAG.SCROLLABLE)
def set_size(self, width, height):
self.obj.set_size(width, height)
def set_pos(self, x, y):
self.obj.set_pos(x, y)
class ButtonGroup(Container):
def __init__(self, parent):
super().__init__(parent)
self.obj.add_flag(lv.obj.FLAG.HIDDEN)
def add_button(self, label, keycode, x, y, width, height):
button = Button(self, label, keycode)
button.set_pos(x, y)
button.set_size(width, height)
def layout(self):
self.obj.layout()
def show(self, flag):
if flag:
self.obj.remove_flag(lv.obj.FLAG.HIDDEN)
else:
self.obj.add_flag(lv.obj.FLAG.HIDDEN)
class NumberPad(ButtonGroup):
def __init__(self, parent):
super().__init__(parent)
self.add_button('1', None, 0, 0, 30, 20)
self.add_button('2', None,35, 0, 30, 20)
self.add_button('3', None,70, 0, 30, 20)
self.add_button('4', None,0, 25, 30, 20)
self.add_button('5', None,35, 25, 30, 20)
self.add_button('6', None,70, 25, 30, 20)
self.add_button('7', None,0, 30, 30, 20)
self.add_button('8', None,35, 30, 30, 20)
self.add_button('9', None,70, 30, 30, 20)
self.add_button('9', None,0, 55, 100, 20)
class ArithmeticPad(ButtonGroup):
def __init__(self, parent):
super().__init__(parent)
self.add_button('+', None, 0, 0, 30, 20)
self.add_button('-', None,35, 0, 30, 20)
self.add_button('*', None,70, 25, 30, 20)
self.add_button('/', None,70, 50, 30, 20)
class Keyboard(Container):
def __init__(self, parent):
super().__init__(parent)
self.number_pad = NumberPad(self)
self.number_pad.set_size(100, 95)
self.number_pad.set_pos(0, 25)
self.number_pad.show(True)
self.arithmetic_pad = ArithmeticPad(self)
self.arithmetic_pad.set_size(100, 70)
self.arithmetic_pad.set_pos(35, 0)
self.arithmetic_pad.show(True)
class Calculator(Container):
def __init__(self):
scrn = lv.screen_active()
super().__init__(scrn)
self.obj.set_style_bg_opa(255, lv.PART.MAIN)
width = scrn.get_width()
height = scrn.get_height()
self.obj.set_size(width, height)
half_height = int(height / 2) - 15
width -= 20
self.text_area = lv.text_area(self.obj)
self.text_area.set_size(width, half_height)
self.text_area.set_pos(10, 10)
self.keyboard = Keyboard(self)
self.keyboard.set_size(width, half_height)
self.keyboard.set_pos(10, half_height + 20)
self.obj.add_event_cb(self.button_pressed_cb, CALC_BUTTON_PRESSED, None)
def button_pressed_cb(self, e):
button = e.get_param().__cast__()
self.text_area.append_text(button.get_keycode())
calc = Calculator()