TL;DR - If worst case frame rate is dominated by the LVGL in memory rendering, optimize it first rather than the transfer rate to the TFT. To understand the situation of your application, measure it.
I recently modified my LVGL app to use dual DMA buffer rendering and though that others may find it interesting.
Configuration: Raspberry Pi RP2040 M0+ Pico @ 125Mhz, ILI9488 320x480 16 bits colors, sufficient RAM to contain 50% of the screen’s pixels (using 2 buffer of 25%) , 8 bits parallel path to the TFT, 15M pixels/sec I/O to the TFT using the RP2040’s PIO, screen updates are dominated by a large chart with 200 points that is rendered from scratch on each update.
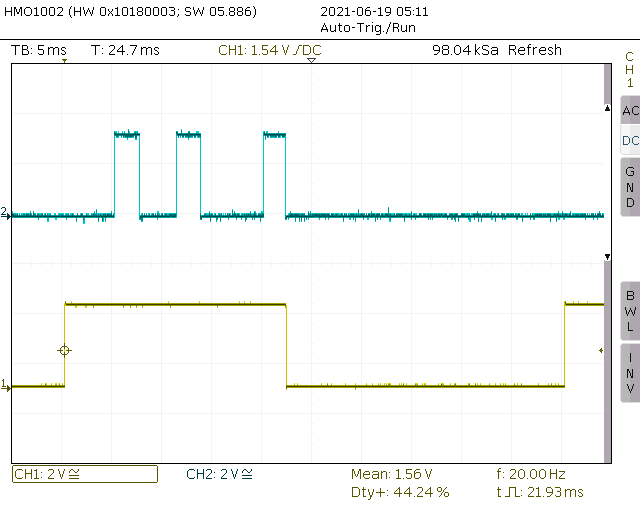
Case 1 - Blocking DMA, rendering continues only when DMA completed. Yellow line shows total time in lv_refr_now() and blue line shows DMA activity. Overall frame time is 22ms.
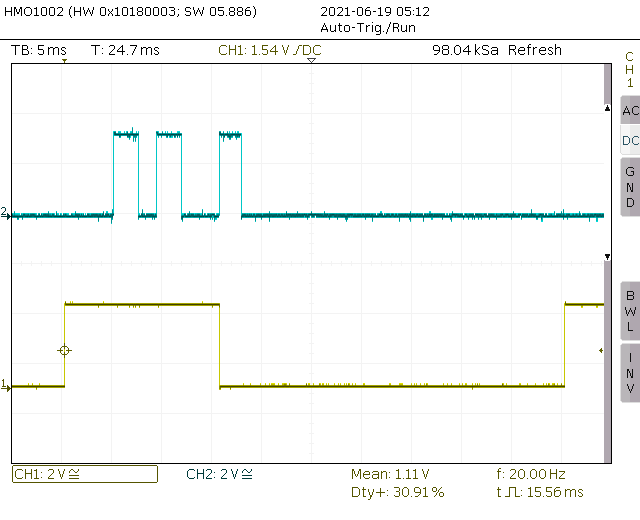
Case 2 - Non blocking DMA. Rendering of the alternate buffer starts while DMA is still active. Frame time is 15.56ms which is 40% speed improvement over case 1. Nice. (Caveat: case 1 could be made faster by using a single buffer of 50% screen (?))
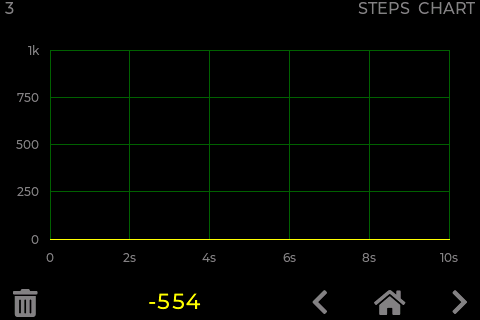
The above two tests were made with the chart having simple data with all points having the same value:
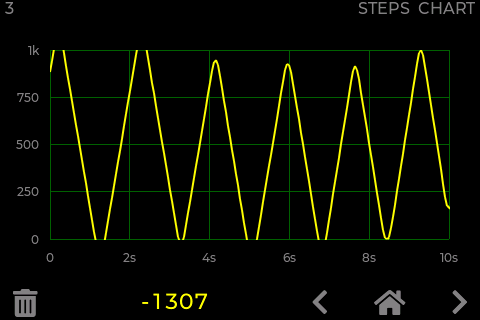
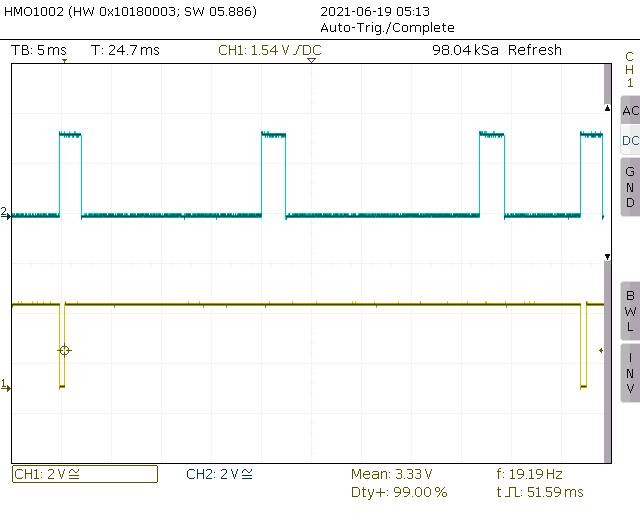
Case 3 - Same as case 2 (non blocking DMA) but with a more complex chart data:
The rendering time increased significantly to a point that the frame time is 51ms and could probably grow even more if the data was were fluctuating more.
About a week ago I found a bug in LVGL when 2 buffers are used. LVGL waited for the buffer to be released in the wrong place. It could also mean a few milliseconds if you used an older version.
Drawing that many lines could be really slow. I’m planning to optimize the line a circle drawing in v8.1.
Was it fixed in 7.x? Can you point me to the commit so I can apply to my ‘fork’ ?
I also wondered abut the screen sharding that LVGL does. The buffers sent to the DMA seems to be in bottom up order (that is, wide rectangles with as many lines it can fit). I wonder if a left to right order will speed thins up (less line segments to render) and less tearing effect (less lines crossing buffer boundary). Is it configurable?
Yes, you are right, top to bottom, increasing y values. I will try left to right updates, to see if it makes any difference. I presume that the change is basically swapping x,y in the sharding logic.
… a couple of minor style suggestions if you don’t mind
If there is nothing to do after an ‘if’, returning immediately saves the reader the need to scroll down to see if anything else is done later. And it eliminates the extra nesting of the ‘else’.
Returning boolean expression can simplify the code (vs. breaking into explicit true/false).
We only add bug fixes to v7 so if it’s not critical I wouldn’t change these parts.
But I applied the first suggestion on v8. (There is no lv_disp_is_double_buf function in v8)
Here is a comparison of chart updates in top to bottom style (normal LVGL) and left to right style (patched LVGL), using 2 buffers (each ~25% of the screen) and non blocking DMA. The update time is dominated by the LVGL in RAM rendering.
I hope that the camera doesn’t introduce artifacts on its own. In real life, the left to right (patched LVGL) seems to be less noisy with this specific data and configuration.
I’ll add a +1 for this for you to “keep in mind” too For “tearing line” sync, need to write to the screens frame memory behind the scanline in the direction of the scanline, which is always fixed, regardless of the users choice of rotation of the screen output via memory address control settings. Most ILI9488 / NT35510 based screens I have used typically have the scanline traversing the screen in portrait orientation, but as I usually want the screen display to be landscape, I have to remap the received frame buffer to achieve the correct rendering direction. I’m assuming the screen in the video has a default physical portrait orientation, which is why left->right rendering in landscape display is less “noisy”, it’s more in line with the scanline direction.
Any idea how to determine the scan direction of a TFT screen?
Also, does the screen itself, beyond the ILI9488 or similar controller has a temporary memory (analog?)? I am thinking if instead of scanning at 60fps I can pause alternate scan times and use them to send data from the MCU.
No, you only have the GRAM associated with the controller available to you. The pixels need constant refreshing from the GRAM; I’ve set the TFT refresh rate down to 30Hz before, and it’s annoyingly flickery. You can still get tearing even at lower TFT refresh rates; it’s a function of writing to the GRAM while the controller is also refreshing the pixels from GRAM; if you’re writing to memory “ahead” of the scanline and the scanline “catches up”, you risk the tearing effect.
The ILI9488 is generally portrait and scans from the top left, going left to right, and then to the next line down. The question is - which corner of the screen is the top left? The MADCTL command controls the mapping of memory to the physical screen pixels to allow rotation; If you set MX (row address order), MY (column address order) and MV (row/column exchange) all to 0 (which is the default) and send pixel data to the screen sloooowly, you’ll see it draw from the top left. I haven’t figured out a better way, unless the manufacturer of your screen provides a diagram showing this - I know BuyDisplay do this. Anecdotally, I have noticed the touch screen connector wraps around at the bottom end of the screen, but I can’t say if that’s always true.
Do you have access to the tearing line on your IL9488? I did (BuyDisplay ER-TFTM035-6). I didn’t use it in conjunction with the LVGL flush, but I did with video playing code and my flushbuffer; I attached an interrupt to the tearing line which set a flag, and the video code would wait after the buffer was full until it saw the flag was set. This technique works well when you’re playing 24fps video and have nothing else to do in between frames; it doesn’t translate well to a realtime UI, tho.
You’ll still need to push the pixels to the GRAM faster than the scan rate, even with the tearing line signal. But I see you mentioned using a parallel interface, so you should be good, I was using 8 bit parallel and could push fullscreen in around 5ms.
I wonder if it’s slow because of the aliasing overhead. Any suggestion for a quick patch of 7.x that will disable the aliasing, just to evaluate speed and quality?
About a week ago I found a bug in LVGL when 2 buffers are used. LVGL waited for the buffer to be released in the wrong place. It could also mean a few milliseconds if you used an older version.
This bug exists in v8.0.1 too, I had to apply the mentioned commit to get double buffering working in parallel. When is the bugfix going to be applied to v8?
Ah, sorry. The workflow of how to make patch releases is still being developed. I searched for commit messaged beginning with fix and cherry-picked what makes sense to release/v8.0. But this commit message begins with perf. We need to be more conscious about commit messages.
I cherry-picked it to now. Do you need to be released and tagged or can you use the release/v8.0 branch?
I cherry-picked it in my fork, no worries. It can wait for the next release.
I’m not an expert on git workflows but this seems to be an error-prone strategy. Furthermore the git graph gets filled with duplicate commits. Is there an existing discussion about the branching strategy?
We have chosen GitLab flow with release branches as a branching strategy. The question is rather how/when/who to cherrypick the fixes to the minor version branches.
From the experience of the past months, it’s quite difficult to cherrypick 100-200 at once before the release.
We can’t do it on every fix either because the branches of minor versions shouldn’t contain “floating” commits, there should be only released content there.

 For “tearing line” sync, need to write to the screens frame memory behind the scanline in the direction of the scanline, which is always fixed, regardless of the users choice of rotation of the screen output via memory address control settings. Most ILI9488 / NT35510 based screens I have used typically have the scanline traversing the screen in portrait orientation, but as I usually want the screen display to be landscape, I have to remap the received frame buffer to achieve the correct rendering direction. I’m assuming the screen in the video has a default physical portrait orientation, which is why left->right rendering in landscape display is less “noisy”, it’s more in line with the scanline direction.
For “tearing line” sync, need to write to the screens frame memory behind the scanline in the direction of the scanline, which is always fixed, regardless of the users choice of rotation of the screen output via memory address control settings. Most ILI9488 / NT35510 based screens I have used typically have the scanline traversing the screen in portrait orientation, but as I usually want the screen display to be landscape, I have to remap the received frame buffer to achieve the correct rendering direction. I’m assuming the screen in the video has a default physical portrait orientation, which is why left->right rendering in landscape display is less “noisy”, it’s more in line with the scanline direction.