Description
Data abort at start lvgl7.0, compiled with full speed optimisation only.
What MCU/Processor/Board and compiler are you using?
SAMA5D3 (ARM Cortex A5) Compiler: IAR for ARM 7.8
What do you experience?
I use the ARM IAR compiler, which allows you to include various optimization strategies. When you turn on full speed optimization and the option “Common subexpression elimination” or CSE, the application crashes in Data Abort. Empirically, I determined that the fall occurs in lv_ll.c i.e. if you compile this file without CSE, then the application works without problems. It has not yet been possible to identify in which particular function the problem occurs.
I’m not sure if this can be called a bug, but version 6.1.2 did not have similar behavior on the same platform and the same compiler. In addition, I always believed that the program should be executed the same way, at any optimization levels.
What do you expect?
Code to reproduce
No specific code to reproduce.
Screenshot and/or video
My educated guess would be that our custom memcpy functions are to blame. It might be worth a try to undo this for lv_ll.c and then compile with optimization.
I think no. I prefixed the functions in lv_ll with the pragma that controls optimization. And the inclusion of CSE in functions using _lv_memcpy does not cause a crash. But the inclusion of CSE in the top-level functions (_lv_ll_ins_head, _lv_ll_ins_prev, _lv_ll_ins_tail, _lv_ll_remove) causes Data Abort.
That’s strange, because I don’t think the underlying logic for linked lists has changed much between versions. I assume you also tried it with the static functions at the bottom. The only explanation I can see is that CSE causes the compiler to optimize away some of the calls to node_set_next and node_set_prev. I’ll have to see if my compiler supports it.
Yes, you were absolutely right, replacing _lv_memcpy_small with native memcpy solved the problem with using CSE optimization. In fact, in the IAR (and Keil, for example) compilers, the memcpy and memset implementations are optimal (i.e., they take into account alignment and block size to use 32 bit operations).
Ours do the same here and here. The main reason we opted for using custom functions was because they offered a significant boost to performance.
I suspect that the compiler may be seeing references to the built-in memcpy and then knowing to skip some optimizations. Page 328 of this IAR PDF seems to support my theory:
Certain C library functions will under some circumstances be handled as intrinsic functions and will generate inline code instead of an ordinary function call, for example memcpy, memset, and strcat.
Now I think we need to figure out what optimization is being done to the lv_memcpy version and not the memcpy version.
Of course I looked at this code (implementation of memcpy replacement). At first glance, everything is fine there. Regarding the IAR documentation, it means that memcpy and memset do not have a source in the library. And it really isn’t, I checked. This is considered a built-in function whose code is generated by the compiler. Probably, if it is possible to have data size at the compilation stage, you can do without calling the function. For example, if you want to copy 8 bytes, then these are two LDR / STR instructions.
@embig71
Does it also solve the problem is you replace _lv_mem_copy_small with memcpyonly in lv_ll.c?
Yes, I replaced _lv_mem_copy_small with memcpy in this file, and the exception DATA_ABORT is gone. This is probably only specific to certain compilers at high levels of optimization.
Thanks.
I’ve checked if we can eliminate the mem copies from this file but the pointer to next and prev is stored unaligned if node size is not dividable with 4. So we need a mem copy here.
Can your debugger tell exactly where does the issue happen? It’d be even better to know if some variables have odd values. But I’m affraid the local variables are optimized out.
I will try to find out, but it is rather difficult to debug the code, at high levels of optimization. It seems to me that the matter is not for access an unaligned address, but in something else. For this platform, I have not yet made an exceptional trap. Although it may be from ARM-9, I will need to try.
Perhaps we should force it to be aligned. It should also give a slight edge to performance.
Ups, I missed that it’s already aligned…
I’ve tried to eliminate the memcpys but it seems a little bit complicated. A node in the linked list is built like this:
N byte data
pointer to the previous node
pointer to the next node
So we need to read a pointer from the Nth position of the node. But the pointer’s size is different with different architectures. So with direct assignment (without copy) it’d be required to handle the different pointer sizes which is ugly and error-prone.
If we can’t find the reason of the crash, I suggest using the built-in memcpy here.
What if we padded the end of the node?
N byte data
X bytes for aligning to native pointer size
pointer to previous node
pointer to next node
(OT: Any reason why the node data is stored at the end instead of the beginning? Most other linked-list implementations seem to use the beginning.)
I rebuilt the project with full optimization and breakpoints on short copy functions. First, the _lv_ll_get_prev function was called, where the _lv_memcpy_small function expanded into the following code:
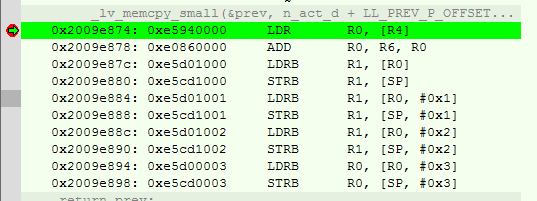
Then, the node_set_next function was called, where the _lv_memcpy_small function expanded into the following code:
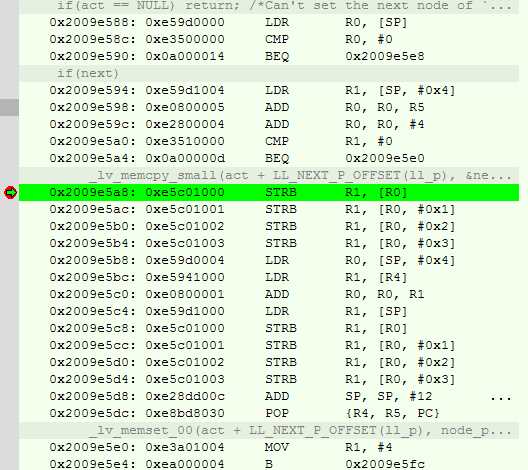
At the moment the second breakpoint was triggered, the following was in the registers:
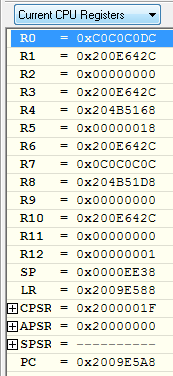
Obviously, the value of R0 is not a valid address (and looks very suspicious), which leads to a drop in the first instruction of the copy procedure. Where the value of the address goes bad, until I understand.
There’s definitely something going on there. I haven’t yet had a chance to try and reproduce it on my hardware.
I still think that we should just eliminate the memcpys here altogether. I can see that it’s generating four STRB instructions just to set the value. That seems quite inefficient, especially given the amount of linked-list traversal used for the style system, etc.
Do I understand correctly that the nodes of a linked list are always aligned to the size of the pointer? Then it really is wise to do something like this:
next = *(void**)(n_act_d + LL_NEXT_P_OFFSET(ll_p));
prev = *(void**)(n_act_d + LL_PREV_P_OFFSET(ll_p));
And the code generated is beautiful:


1 Like
From what @kisvegabor said, it sounds like they aren’t always aligned. My suggestion is to guarantee alignment so that we can do what you’re suggesting. Using memcpy seems like a strange workaround.
@embeddedt
I started to reimplement the linked list module to place prev and next to the beginning of the nodes but I realized there could be a problem with Micropython.
If a linked list node would look like this:
struct _lv_ll_node_t * prev;
struct _lv_ll_node_t * next;
uint8_t first_byte;
}lv_ll_node_t;
_lv_ll_ins_head() would return &node->first_byte therefore not the allocated address would be saved in GC_ROOTs and garbage collector would collect them.
CC @amirgon
Hi, @kisvegabor.
Why change something here? In C, members of structures are always aligned to the width of the controller, if you do not precede the declaration of the structure #pragma pack (). Then, if the beginning of the allocated memory is aligned to the bit width of the controller, all members of the structure will be aligned as well. Or is it talking about 8-16 bit platforms? For these cases, you can force #pragma pack (4). I am wrong?