Hi all,
I have been trying to get to the bottom of an issue for a very long time. My hardware is the AMD Zynq Ultrascale+ MPSOC on which I have implemented a display port driver and use XHCI USB for the touch screen. I am running LVGL on a home grown SMP FreeRTOS port on the Application processor which has 2 x 1.2GHz A53 cores and two seperate iterations of FreeRTOS on the two R5 cores for some control processes.
The display interface uses double buffered(Full Screen sized buffers) direct mode with DMA and the hardware automatically changes DMA buffer addresses only during V-sync. I am also using a full HD 1080p with ARGB8888 configuration which I think might be a bit of a corner case.
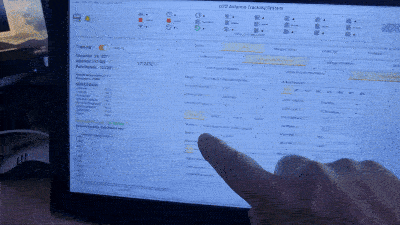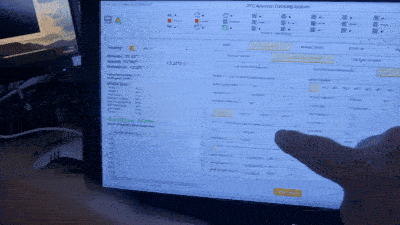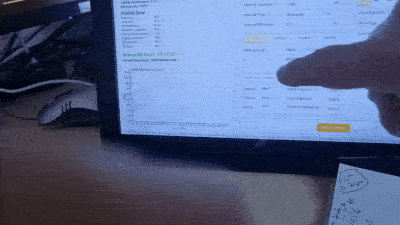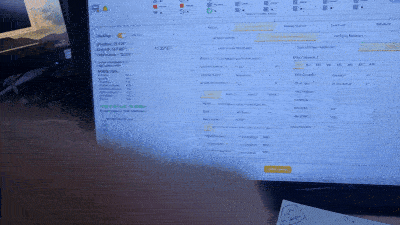
Since I first bought up my code on the hardware just over a year ago I have an issue where I see black rectangles appearing when the display is being scrolled by dragging with the touch screen. I have tried implementing the driver in many ways and it always ends up with the same result, so I am now wondering if there may be some problem with the LVGL library.
I have attached a video of the problem, sorry it is not great quality as I have had to compress it a lot to make it uploadable on here. It is slightly worse than it shows on the video because the frame rate of my camera is not that great it doesn’t grab a true representation of the frequency of the rectangles, but I think it’s enough to see the issue. The rectangles are also always confined to the area of the screen which is actually scrolling only and not anywhere else.
If anyone has any ideas about how to go about debugging this issue I would most appreciative as I am pretty much out of ideas right now. I find I can’t reproduce the problem when stepping through the code for example, it’s all very difficult to deal with. Any suggestions please? ![]()
Thank you,
Kind Regards,
Pete