lvgl version:V8.2
We used lv_obj_set_style_bg_img_src to set the background for all obj, and there are many background images. The frame rate has a great impact, only 20FPS, which is more stuck when sliding. Our device is a quad-core CPU, and only 1 CPU is working at full capacity. We hope to optimize the frame rate through parallel computing. What are the suggested optimization points? Thank you.
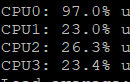
lv_draw_sw_blend_basic comparison affects performance.
Parallel rendering is not supported in LVGL yet.
Some questions:
- What is the speed of the CPU?
- What is the resolution of the display?
- Have you enabled -O2 or -O3 optimization?
- Have you disabled
LV_USE_ASSERTS_*inlv_conf.h?
But “What is the resolution of the display?” E.g. 800x480.
If you are using a lot of images and blending takes a lot of time, be sure to use LV_IMG_CF_TRUE_COLOR (and not LV_IMG_CF_TRUE_COLOR_ALPHA) if the image has no alpha channel.
Thanks.
Display: 480*480.
Setting it to LV_IMG_CF_TRUE_COLOR in decoder_info has some effect, but it has little effect. any other suggestions ?
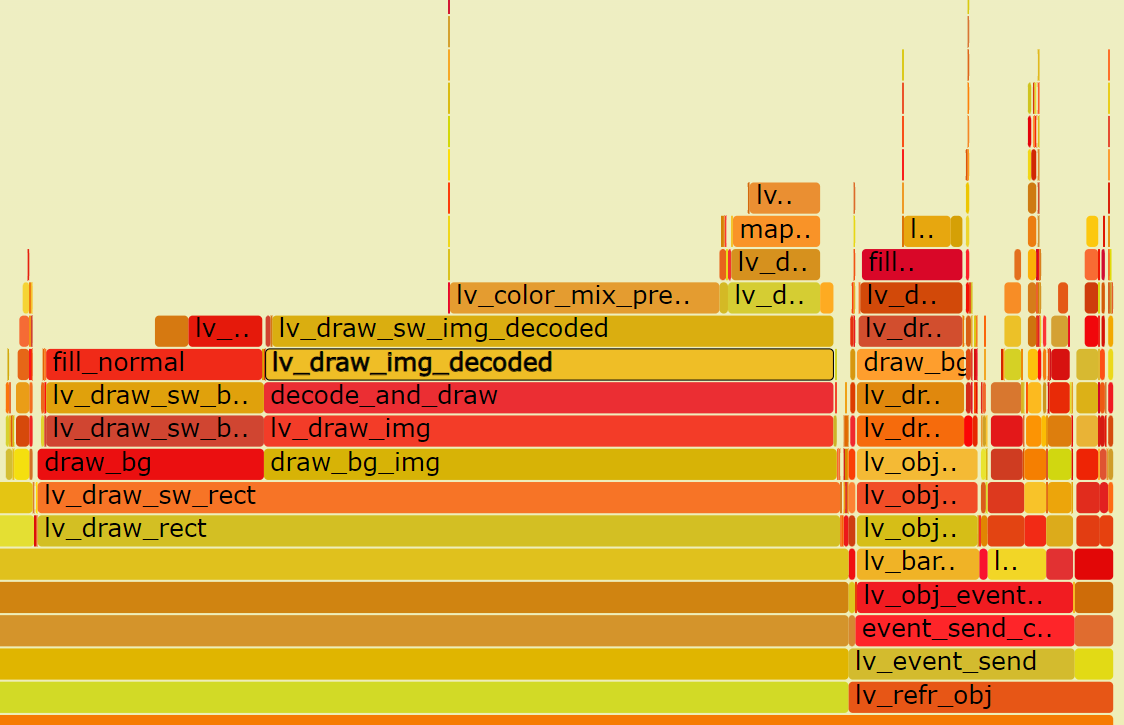
With that speed on a such a small display it should be much faster.
It seems significant amount of time is spent by lv_color_mix_premultiply. It can happen when you use recolored images. How large images are you recoloring?
BTW, what is this great profiler tool? 
Profiler tool: https://github.com/brendangregg/FlameGraph.
It is indeed caused by recolored images. The largest picture of recolor is about 400*400. This question has troubled me for a long time. 
1 Like
Thanks!
Just to be sure this is the problem: is much faster if you disable recoloring?
36 FPS is still not that much.
Please add the whole FlameGraph SVG.
lv_draw_gaussian_blur_specific_radius takes ~30% time which is not a built in function so I can’t comment on it.
Recoloring also takes another ~30% for which I can’t imagine a more effective algorithm. Maybe unrolling the loop here as:
for(i = 0; i < buf_size - 8; i+=8) {
rgb_buf[i + 0] = lv_color_mix_premult(premult_v, rgb_buf[i + 0], recolor_opa);
rgb_buf[i + 1] = lv_color_mix_premult(premult_v, rgb_buf[i + 1], recolor_opa);
rgb_buf[i + 2] = lv_color_mix_premult(premult_v, rgb_buf[i + 2], recolor_opa);
rgb_buf[i + 3] = lv_color_mix_premult(premult_v, rgb_buf[i + 3], recolor_opa);
rgb_buf[i + 4] = lv_color_mix_premult(premult_v, rgb_buf[i + 4], recolor_opa);
rgb_buf[i + 5] = lv_color_mix_premult(premult_v, rgb_buf[i + 5], recolor_opa);
rgb_buf[i + 6] = lv_color_mix_premult(premult_v, rgb_buf[i + 6], recolor_opa);
rgb_buf[i + 7] = lv_color_mix_premult(premult_v, rgb_buf[i + 7], recolor_opa);
}
for(; i < buf_size; i++) {
rgb_buf[i] = lv_color_mix_premult(premult_v, rgb_buf[i], recolor_opa);
Could you try it?
This also might be helpful: https://github.com/lvgl/lvgl/pull/3499
- The draw cache optimization has little effect. Because lv_obj_set_style_bg_img_src is used to set the new img src in memory when sliding.
- Note that lv_color_mix_premult does have a 30% optimization effect. Currently I am using lvgl 8.2 and cannot unroll the loop.
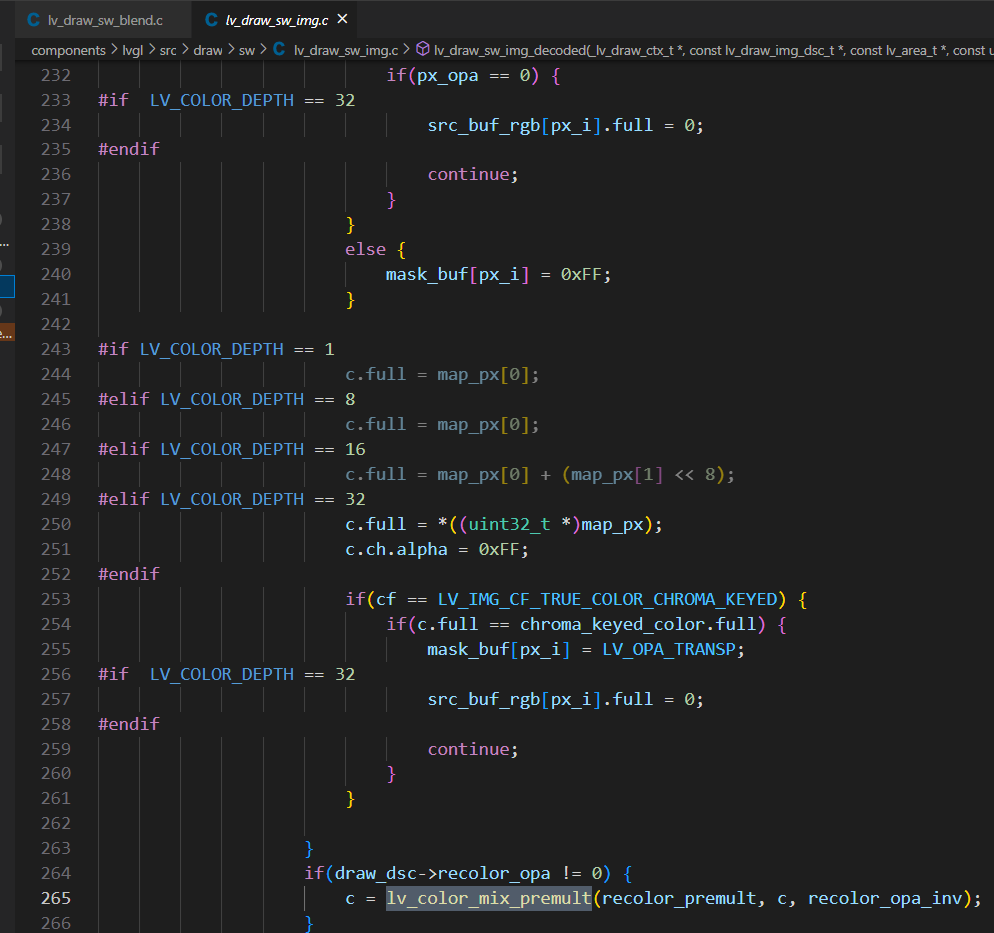
30% of lv_draw_gaussian_blur_specific_radius has been optimized away ![]() .
.
Updating to v8.3.1 should not be that complicated. Can you give it a try?
Cooool! How many FPS now?
- The current frame rate has been optimized to 36 FPS. Thanks for the support.
- I’ll try lv_color_mix_premult unroll the loop, maybe a little later. But I’m not quite sure where is the optimization logic point of unroll the loop? The process is the same.
- Are there any plans to support multithreading?
- We are planning to do a 480*800 or 720p project, and the frame rate is very worrying. Currently, lvgl has not adapted to the G2D hardware acceleration commonly used on the Linux platform. Is there any plan?
The for cycle has some overhead. Like i < buf_size (condition check), or i++ (increment a variable) and it does matter that if this overhead is paid for every cycle or only for every 8th cycle.
Yes, in v9 (under development) we are planning to prepare the architecture top support it.
I haven’t heard of G2D so far and couldn’t really find any useful resources in Google. Can you link some docs?
G2D is a Chinese chip company’s 2d acceleration solution. It has been confirmed by the corresponding company, and they have already made the adaptation of G2D to lvgl. G2D mainly completes layer mixing/rotating/scaling functions. No English documentation was found for the time being.
http://files.lindeni.org/lindenis-v5/documents/soft_design/System/sunxi%20g2d模块使用文档.pdf
It’s sad. Anyway, if someone is interested in adding G2D support to LVGL I’d be happy to assist. It seems it fits well to LVGL’s architecture.